Unity_Lesson
3-3 報酬とエピソード完了
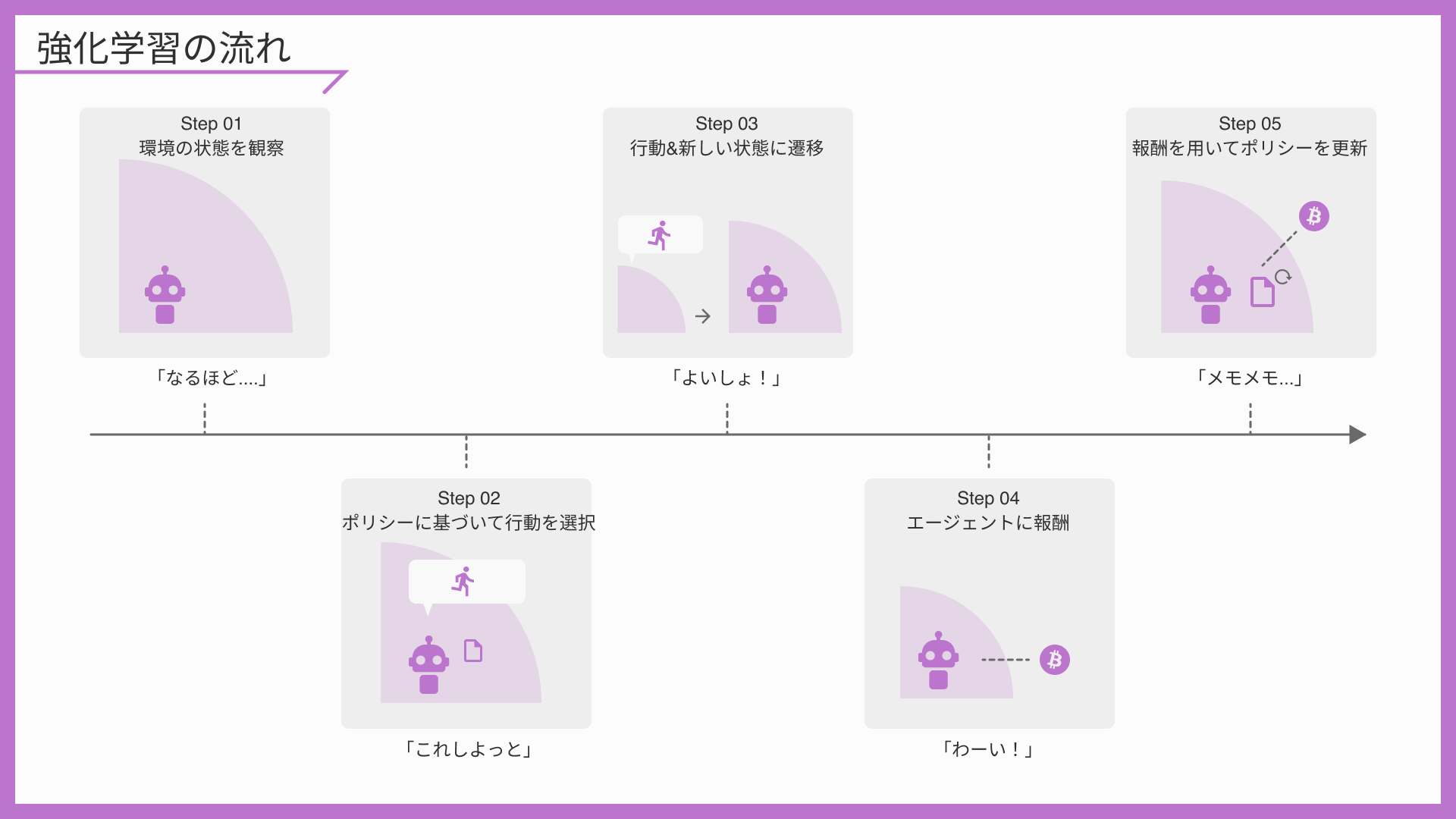
エージェントが「行動」を行ったことにより、環境に変化が起こる。 ↓でいう4番目と5番目で、これを評価しポリシーを更新する過程になる
報酬とは
「報酬」はエージェントの「行動」に対する環境からの評価です。強化学習アルゴリズムは、エージェントが時間の経過とともに高い「収益」を獲得するように「行動」を最適化します。
「強化学習サイクル」では、エージェントは「行動」の実行結果に応じて「報酬」を受け取り、その「報酬」に応じて「ポリシー」を更新します。
現在のステップの即時報酬の設定
現在のステップの「即時報酬」を設定するには、AgentクラスのAddReward()とSetReward()を使います。これらを設定しない場合の即時報酬は「0.0」になります。
・void AddReward(float increment):現在のステップの即時報酬に加算
・void SetReward(float reward):現在のステップの即時報酬を設定
現在の累計報酬の取得
現在の「累計報酬」を取得するには、AgentクラスのGetCumulativeReward()を使います。これは、エピソード開始から現在までの累計報酬ですが、現在のステップの即時報酬は含まれていません。
また、現在が何ステップ目であるかを取得するには、AgentクラスのStepCountを使います。
・float GetCumulativeReward():現在の累計報酬の取得
・int StepCount:現在が何ステップ目であるかの取得
報酬シグナル
「Unity ML-Agents」の「報酬」には、先で説明した環境によって与えられる「環境報酬」の他に、未知の状態に訪れることに対して与えられる「Curiosity報酬」と、人間のデモを模倣することに対して与えられる「GAIL報酬」があります。これら報酬をまとめて「報酬シグナル」と呼びます。
・環境報酬:環境によって与えられる報酬
・Curiosity報酬:未知の状態に訪れることに対して与えられる報酬
・GAIL報酬:人間のデモを模倣することに対して与えられる報酬
報酬を設定する際のポイント
「報酬」を設定する際に気をつけるポイントを紹介します。
・「エピソード結果」に対する報酬は、「結果に繋がる行動」に対する報酬よりも、良い学習に繋がる
ゲームの勝敗に対して報酬を与えた方が、良い学習に繋がります。
・1エピソードの報酬の値は、「- 1.0 ~ 1.0」の範囲内に納まる程度が望ましい
過度に大きな報酬は、学習効率が悪くなることがあります。
・プラス報酬はマイナス報酬よりも、良い学習に繋がる
過度に大きなマイナス報酬を与えると、プラス報酬に繋がる行動であっても、選択しなくなる場合があります。
エピソード完了とは
「エピソード完了」の設定方法には次の2種類の方法があります。
・ EndEpisode():エピソード完了
・ MaxStep:エピソードの最大ステップ数
・EndEpisode()
任意のタイミングで「エピソード完了」を行うには、AgentクラスのEndEpisode()を使います。
・MaxStep
「Max Step」はエピソードの最大ステップ数です。
エピソードのステップ数がこれを超えると、「エピソード完了」となります。 「0」を指定すると、無制限になります。
「Max Step」はAgentクラスを継承したスクリプトの「Max Step」で設定します。
エピソード完了を設定する際のポイント
「エピソード」を設定する際に気を付けるポイントを紹介
・学習に必要な要素をすべて含みつつも、なるべく少ないステップ数で終わるようにエピソードを設定
1エピソード完了までに時間がかかる学習環境は、学習効率が悪くなります。
・エージェントがエピソード完了まで辿り着かないことがある環境では、必ず「Max Step」を設定
エピソード完了ができず、学習が進まなくなることを防ぎます。